今天要來介紹Python 網路爬蟲 Web Crawler
1.連線到特定網址,抓取資料
2.解析資料,取得實際想要的部分
盡可能讓程式模仿一個普通使用者的樣子
使用內建json模組即可
使用第三方套件BeautifulSoup來做解析
PIP套件管理工具:安裝Python時,就一起裝在電腦裡了
安裝BeautifulSoup:pip install beautifulsoup4
1.太過於直接,無模仿普通使用者,故訪問被拒絕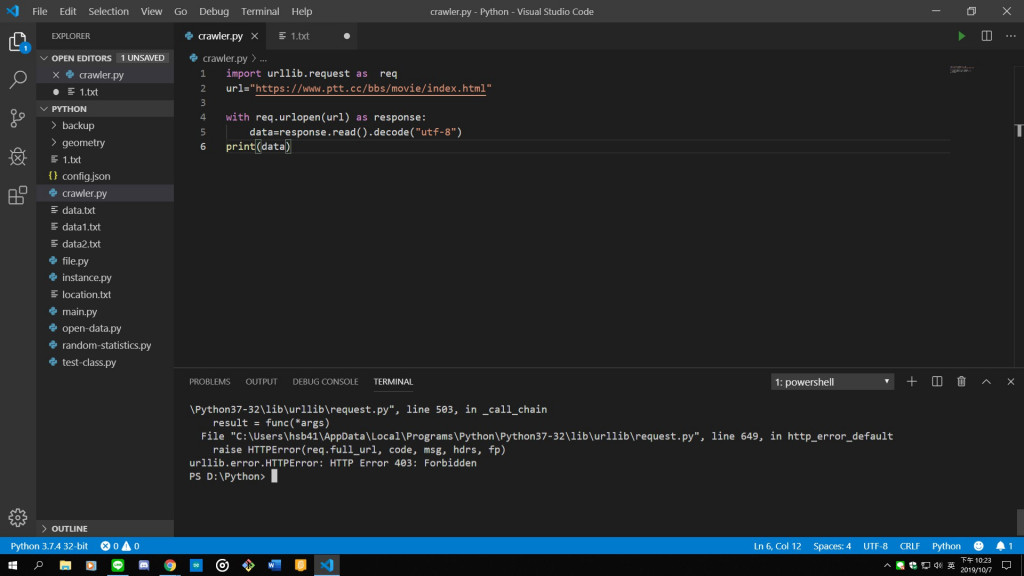
2.模仿普通使用者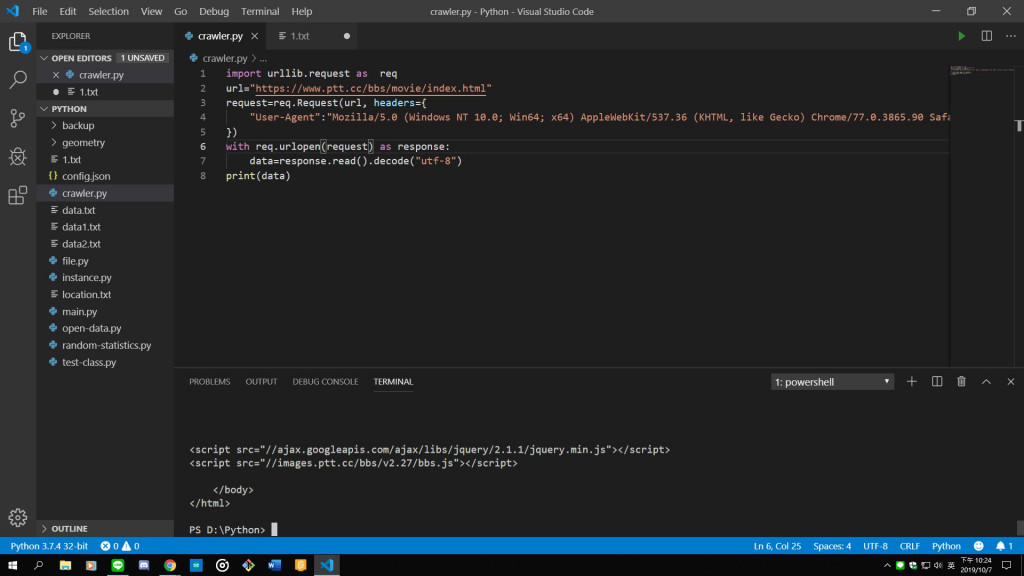
3.安裝第三方套件BeautifulSoup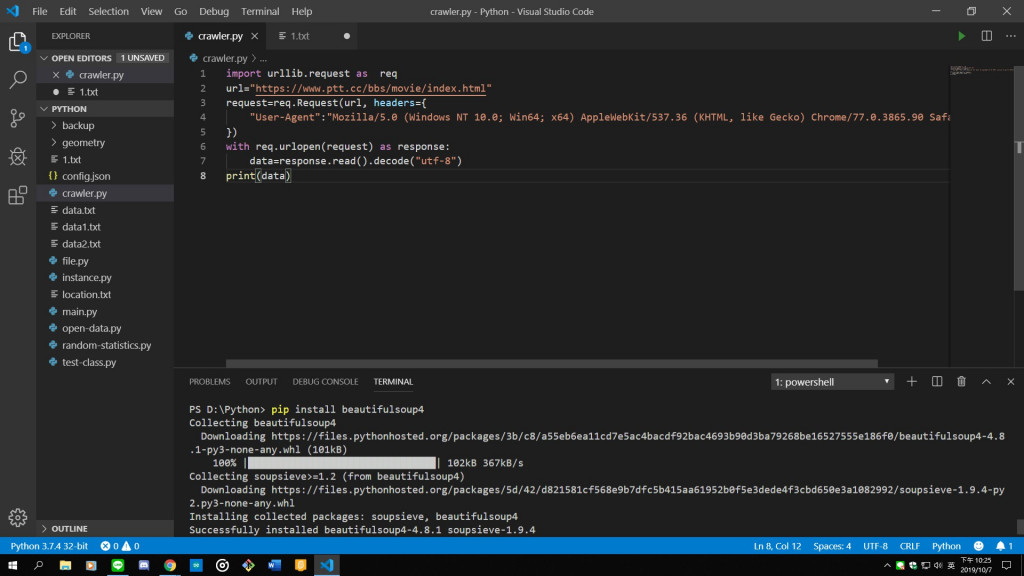
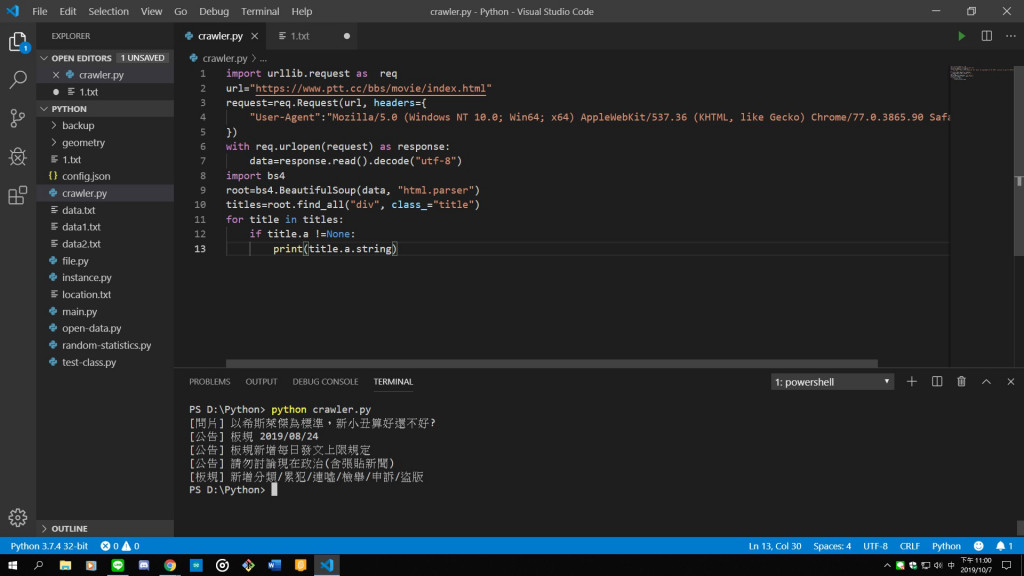
4.抓取網頁標題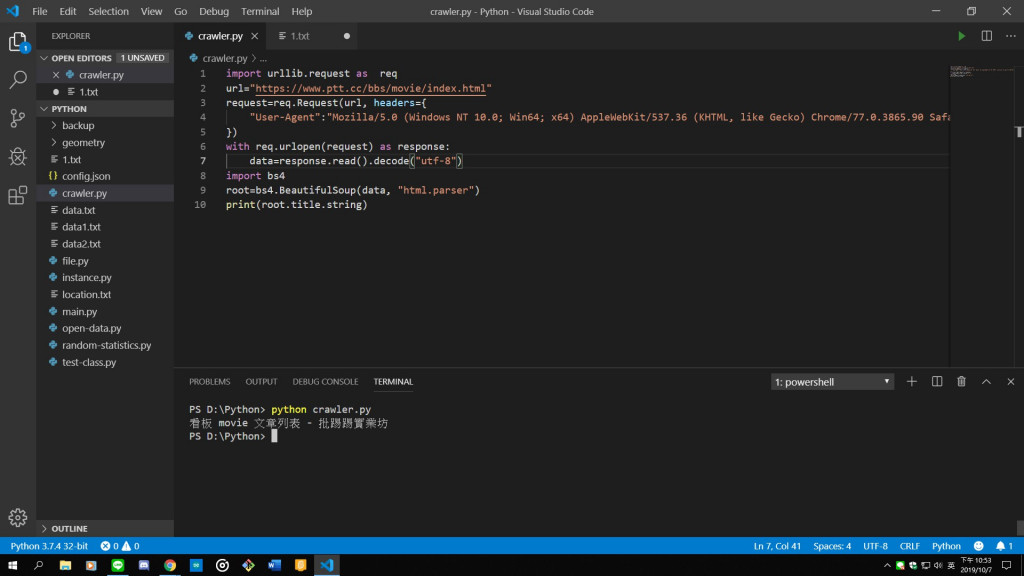
5.抓取單一文章標題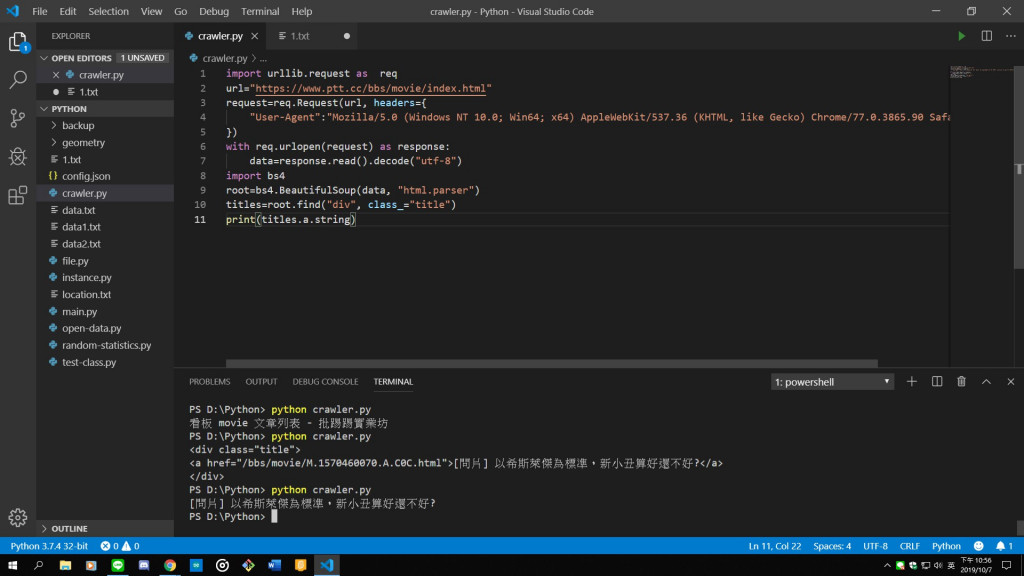
6.抓取所有文章標題